311CNICAS E ALGORITMOS PARA AGRUPAR FOTOGRAFIAS...
23
TÉCNICAS E ALGORITMOS PARA AGRUPAR FOTOGRAFIAS DIGITAIS João Mota [email protected] Abstract. Com a crescente popularidade das máquinas fotográficas digitais, a organização, gestão e agrupamento de milhares de fotografias tornou-se um problema enfrentado por fotógrafos profissionais e amadores. Neste documento são abordadas diversas estratégias e métodos utilizados na automatização des- ses processos, onde são consideradas as diversas características das fotografias digitais: características semânticas, meta-informação, e características de con- teúdo ou características de baixo-nível (cor, textura, forma). São ainda analisa- das as vantagens e lacunas dos estudos actualmente mais relevantes nesta área. E por fim é proposta uma solução que tenta conciliar tais vantagens, tentando também suprimir as deficiências de cada abordagem. 1 Introdução O aparecimento de câmaras fotográficas digitais e a sua forte aceitação, permitiu aos adeptos da fotografia despreocuparem-se com os custos de revelação e consequente- mente acumularem uma elevada quantidade de fotografias. Esta evolução tecnológica, ao provocar a mudança da imagem em papel para a imagem digital, originou altera- ções nas práticas dos utilizadores. Os reduzidos custos das fotografias digitais deixa- ram de limitar a liberdade para fotografar, desencadeando o crescimento das colec- ções fotográficas e uma crescente tendência para o aparecimento de fotografias muito similares, por vezes quase indiferenciáveis. Não só o utilizador passou a tirar mais fotografias, intensificando o aumento das imagens da sua colecção, como a partilha das mesmas passou a estar mais facilitada e a ser uma experiência mais global, como mostram alguns locais na Internet, como por exemplo o Flicker. Todas estas alterações na actividade fotográfica, em particular o aumento drástico do número de fotografias, exigem a necessidade de ferramentas que ajudem o utiliza- dor na organização, gestão e procura automática de fotografias. É neste sentido que pretendo desenvolver uma aplicação que facilite a organização de qualquer colecção fotográfica, através do agrupamento automático das fotografias, usando características e atributos relevantes para o utilizador, facilitando assim a gestão e escolha das melhores. Ao dispor de colecções de milhares de fotografias os utilizadores deparam-se com a dificuldade de as organizar. Embora, de acordo com Frohlich e al. [Frohlich 2002], são poucos os utilizadores que sistematicamente organizam as suas colecções fotográ- ficas, é dessa organização que dependem as futuras actividades de gestão e pesquisa
Transcript of 311CNICAS E ALGORITMOS PARA AGRUPAR FOTOGRAFIAS...

TÉCNICAS E ALGORITMOS PARA AGRUPAR FOTOGRAFIAS DIGITAIS
João Mota
Abstract. Com a crescente popularidade das máquinas fotográficas digitais, a organização, gestão e agrupamento de milhares de fotografias tornou-se um problema enfrentado por fotógrafos profissionais e amadores. Neste documento são abordadas diversas estratégias e métodos utilizados na automatização des-ses processos, onde são consideradas as diversas características das fotografias digitais: características semânticas, meta-informação, e características de con-teúdo ou características de baixo-nível (cor, textura, forma). São ainda analisa-das as vantagens e lacunas dos estudos actualmente mais relevantes nesta área. E por fim é proposta uma solução que tenta conciliar tais vantagens, tentando também suprimir as deficiências de cada abordagem.
1 Introdução
O aparecimento de câmaras fotográficas digitais e a sua forte aceitação, permitiu aos adeptos da fotografia despreocuparem-se com os custos de revelação e consequente-mente acumularem uma elevada quantidade de fotografias. Esta evolução tecnológica, ao provocar a mudança da imagem em papel para a imagem digital, originou altera-ções nas práticas dos utilizadores. Os reduzidos custos das fotografias digitais deixa-ram de limitar a liberdade para fotografar, desencadeando o crescimento das colec-ções fotográficas e uma crescente tendência para o aparecimento de fotografias muito similares, por vezes quase indiferenciáveis. Não só o utilizador passou a tirar mais fotografias, intensificando o aumento das imagens da sua colecção, como a partilha das mesmas passou a estar mais facilitada e a ser uma experiência mais global, como mostram alguns locais na Internet, como por exemplo o Flicker.
Todas estas alterações na actividade fotográfica, em particular o aumento drástico do número de fotografias, exigem a necessidade de ferramentas que ajudem o utiliza-dor na organização, gestão e procura automática de fotografias. É neste sentido que pretendo desenvolver uma aplicação que facilite a organização de qualquer colecção fotográfica, através do agrupamento automático das fotografias, usando características e atributos relevantes para o utilizador, facilitando assim a gestão e escolha das melhores.
Ao dispor de colecções de milhares de fotografias os utilizadores deparam-se com a dificuldade de as organizar. Embora, de acordo com Frohlich e al. [Frohlich 2002], são poucos os utilizadores que sistematicamente organizam as suas colecções fotográ-ficas, é dessa organização que dependem as futuras actividades de gestão e pesquisa

de fotos. O desenvolvimento de uma aplicação que agrupe essa diversidade de fotos, de maneira a gerar colecções organizadas leva-nos à necessidade de conhecer quais os factores de agrupamento mais relevantes.
Sendo que automatizar o agrupamento efectuado manualmente pelos utilizadores é o principal objectivo dos sistemas analisados e do sistema proposto neste documento, surge-nos a questão: quais as práticas mais comuns na gestão e organização de foto-grafias? A resposta a essa questão [Kirk 2006] [Frohlich 2002] [Rodden and Wood 2003] identifica as seguintes características de agrupamento de fotografias mais rele-vantes para o utilizador, sendo elas: o evento ou ocasião em que a foto foi realizada, semelhanças visuais e categorias ou temas abordados através das fotos. É focado nes-ses principais métodos de organização que irá ser desenvolvido do nosso sistema.
Apesar de encontrados os hábitos mais comuns dos utilizadores, encontramos algumas dificuldades. Cada utilizador tem costumes próprios na organização das suas fotos e cada foto simboliza um momento que poderá não ser descrito pela própria imagem ou informação a ela anexada. Por vezes o contexto, a situação, em que foi tirada influência o método de organização no respectivo álbum, e é na identificação e descrição desse contexto que se situa a maior dificuldade.
A dificuldade em anotar todas as fotos, com todas as palavras-chave que descre-vam todo o conteúdo e contexto da fotografia, origina colecções fotográficas onde a interpretação das fotografias é subjectiva, e a tarefa de organização e agrupamento das mesmas torna-se mais difícil.
Não sendo viável o agrupamento e organização através de palavras-chave que caracterizem as fotos, teremos que usar outras abordagens que o façam. Uma solução para a extracção de contexto pode ser obtida através da correlação das imagens utili-zando a data e tempo das fotografias. Esta abordagem organiza as fotografias crono-logicamente de modo a identificar diferentes eventos. Mas até o próprio conceito de evento poderá ser abordado de diferentes maneiras por diferentes utilizadores. Mas será que o utilizador quer realmente agrupar as suas fotografias por eventos, ou gosta-ria de agrupar as fotografias por similaridades ou outra métrica de relacionamento? Um sistema que se adapte a diferentes categorias de utilizadores terá que considerar informação díspar da informação contextual.
Juntamente com a informação contextual disponibilizada, podemos analisar as características do conteúdo das imagens. Esta segunda perspectiva aproxima o nosso problema às técnicas utilizadas nos sistemas de recuperação de imagens, onde as características de baixo-nível ajudam na caracterização da fotografia, possibilitando diversos géneros de agrupamento. Consequentemente, novas questões surgem: quais as melhores características para descrever imagens, em particular imagens fotográfi-cas? Qual a utilidade de cada característica no agrupamento de imagens vs recupera-ção de imagens? Como extrair tais características? Por fim, como correlacionar os diferentes descritores extraídos da imagem?
Tendo obtido um conjunto de descritores que caracterizem uma fotografia, será necessário relaciona-lo com descritores de outras fotografias para obtermos um valor que descreva a similaridade entre elas, e ao qual denominamos métrica de similarida-de. Novamente surge-nos outra questão: Qual a melhor maneira para relacionar des-critores dependendo do tipo de descritores extraídos.
Existem diversas soluções desenvolvidas actualmente, sendo que a maioria dessas soluções focam apenas o agrupamento de imagens baseado em eventos. Entenda-se

por evento uma actividade ou conjunto de actividades relacionadas entre si e realiza-das num intervalo de tempo contínuo, como por exemplo, uma festa de aniversário, natal, etc. No seguimento desta perspectiva, a maioria das soluções explora exausti-vamente as características temporais ignorando as características de conteúdo de ima-gem. Esta lacuna na comparação de fotos limita os tipos de agrupamentos proporcio-nados pelas soluções desenvolvidas.
Tendo em conta as limitações das soluções existentes para organizar fotografias, proponho um sistema que tente abranger o máximo de informação possível de cada fotografia, como por exemplo: informação semântica associada à fotografia pelo utili-zador (ex: legenda), meta-informação gerada pelos dispositivos fotográficos, caracte-rísticas de cor e textura ou identificação de formas significantes nas fotos. Nunca des-prezando as limitações computacionais impostas a qualquer aplicação end-user, tais como, tempo ou memória necessária ao processamento dos diversos algoritmos.
Dada a subjectividade na análise de fotografias, tentarei tornar o sistema bastante parametrizável, dando a possibilidade do utilizador escolher os pesos de cada género de agrupamento. Ao dispor do controlo de diversos parâmetros, o utilizador poderá adaptar o sistema ao tipo de fotografias da sua colecção e aos seus objectivos de agru-pamento.
Para conseguir esta diversidade de agrupamentos, irei considerar técnicas de detec-ção de eventos que analisam a informação contextual e temporal disponível. Irei tam-bém implementar algumas soluções conhecidas da área de recuperação de imagens (CBIR), adaptando-as ao agrupamento de fotografias baseado no seu conteúd. Neste segundo género de agrupamento tentarei abranger o maior número possivel de carac-terísticas de baixo-nível (cor, textura, forma), de modo a enriquecer a descrição do seu conteúdo.
2 Estudos mais Relevantes na Análise e Agrupamento de Fotografias Digitais
Durante estes últimos anos tem-se observado um crescente interesse na área da análi-se de imagem, principalmente devido ao crescimento massivo das máquinas fotográ-ficas digitais. Desde então, os utilizadores têm exigido aplicações que os ajudem a gerir e organizar as suas fotografias de modo eficiente e simples.
Entre as diferentes abordagens desenvolvidas para o agrupamento de imagens, encontramos uma grande incidência na utilização da informação temporal como crité-rio base dessa organização. A complementar este critério são frequentemente utiliza-das abordagens da área de recuperação de imagens baseada no conteúdo (Content-Base Image Retrieval - CBIR). A análise do conteúdo das imagens é efectuada através da extracção de características descritoras das mesmas, denominadas por característi-cas de baixo-nível e características semânticas. No conjunto de características de bai-xo-nível encontramos 3 categorias: cor, textura e forma. Entre as características semânticas, as mais comuns são as legendas que os utilizadores têm que associar manualmente a cada fotografia.

Adquirido o conjunto de descritores de cada fotografia, procede-se ao seu agrupa-mento, frequentemente efectuado através de técnicas de clustering ou usando métricas de cálculo de similaridade de conteúdo e ou de contexto.
Nas secções seguintes são descritas as três técnicas usadas para agrupar imagens, sendo elas: agrupamento baseado em eventos, data/tempo, baseado em anota-ções/legendas e baseado no conteúdo de imagem. São também abordadas diversas técnicas de recuperação de imagens que, como já foi referido anteriormente, estão associadas ao agrupamento baseado no seu conteúdo.
2.1 CBIR – Content Based Image Retrieval
Dado que a organização e gestão de colecções fotográficas é realizada para facilitar as futuras tarefas de pesquisa e procura de fotos, será interessante analisar os mecanis-mos utilizados na área da recuperação de imagens (CBIR), na medida em que estes poderão ser utilizados na sua organização. Esta abordagem de cálculo de similaridade já é seguida por alguns autores, cujo trabalho é descrito nesta secção.
Dentro da análise de conteúdo de imagem existem três grandes categorias de des-critores: a cor, a textura, e a forma geométrica. Usando estes descritores são definidas métricas de similaridade, a partir das quais se agrupam as fotos.
2.1.1 Cor Das três categorias de características de baixo-nível referidas, a cor é a característica mais trivial de analisar, sendo portanto, a característica mais utilizada.
Os Histogramas são a técnica mais conhecida neste tipo de características. Mas a simples utilização de histogramas não nos fornece informação suficiente. Diversos estudos têm expandido a utilização dos histogramas a técnicas mais complexas e obtentoras de descritores de imagem mais precisos. A combinação da cor com o espa-ço de imagem é um desses exemplos: utilizar histogramas diferentes para segmentos de imagem diferentes.
Outra técnica de extracção de descritores de imagem é apresentada em [Alghbari 2006]. Nesta abordagem é gerado o histograma da imagem, através do qual a imagem é segmentada em regiões de cores diferentes. Através dessas regiões poderemos extrair as cores representativas da imagem e utilizá-las na comparação das imagens.
Outro estudo [Huang 1997] analisa a similaridade das imagens através da correla-ção entre as cores presentes na imagem. Este estudo utiliza a relação espacial entre cores para caracterizar as imagens e posteriormente definir a similaridade das mes-mas.
Wei e al abordam o problema da recuperação de imagens através da combinação das características da cor e da textura [Wei 2005]. As imagens são segmentadas atra-vés da cor e textura, obtendo regiões pertencentes a objectos e regiões de fundo.
A transformação da imagem do domínio espacial para o domínio da frequência também tem vindo a ser explorada, obtendo resultados satisfatórios. No seguimento desta abordagem, Biren N. Shah propõe uma descrição da imagem através da quanti-zação da cor [Shah 2004]. Biren N. Shah através da representação da frequência da imagem propõe a selecção das cores representativas da imagem. No seu ponto de vis-ta as cores não uniformemente distribuídas são as que melhor representam as ima-

gens. O autor utiliza a variância de cada cor para definir a importância dessa cor na imagem.
Outra técnica que dá ênfase às cores menos dominantes, não desprezando as cores mais dominantes, é proposta por Chitkara et al. [Chitkara 2000]. Esta técnica permite a obtenção de uma performance 50% superior à obtida com o uso de histogramas de cor globais (GCH) e de 25% relativamente ao uso de color coherence vectors (CCV). Para além da performance esta técnica permite poupar 75% de espaço de armazena-mento quando comparado com GCH e 85.5% em relação a CCV, pois cada imagem é quantificada num número fixo de cores.
Por vezes também nos deparamos com questões de limitação de recursos, para tal também são abordadas técnicas que permitem contornar essas limitações mantendo as capacidades de análise. Numa dessas abordagens [Smith and Chang 1995] o objectivo passa pela redução da dimensão do espaço de cores e ao mesmo tempo adquirir a capacidade de localizar informação de cor no espaço das imagens. Ao criar uma representação mais compacta das imagens diminui a complexidade de análise provo-cada pelo elevado número de cores existentes nas imagens fotográficas.
2.1.2 Textura A textura é uma particularidade da organização das cores das imagens. Sendo uma particularidade das cores, as texturas permitem obter resultados mais eficazes na iden-tificação de similaridades. De seguida descrevem-se algumas das técnicas de análise de texturas mais relevantes.
Em [Saha 2004] Saha et al utiliza a textura como característica descritora de uma imagem. Através da imagem é construida uma matriz denominada texture co-
occurance matrix que reflecte os padrões de intensidade observados. Após obtida a matriz, são calculadas medidas estatísticas como a entropia, energia e texture
moments, e utilizam-se essas medidas para definir níveis de semelhança entre ima-gens.
Outra utilização da textura é apresentada em [Jalaja 2005], onde são descritos métodos estruturais de análise da textura, visando aproximação à visão humana. São apresentadas duas caracterizações de padrões locais: a primeira é uma extensão ao espectro de textura de He e Wang [He and Wang 1990][He and Wang 1991] para uma janela de 5x5 com novas características estruturais que permitem a captura de padrões locais tais como faixas verticais e horizontais, alternância de pontos escuros e pontos brilhantes, etc. A segunda é um método que caracteriza padrões como variações de contrastes em janelas de 5x5.
No estudo efectuado por Rivaz e Kingsbury [Rivaz 1999], é exposta uma nova complex wavelet transform que tem como objectivo a aproximação das características da técnica de Gabor e a derivação de uma métrica de distância baseada em hipóteses estatísticas, que obtenha melhor performance que as métricas usuais. Esta técnica combina velocidade e precisão, sendo um bom método de extracção de características de texturas.
2.1.3 Formas A detecção de formas geométricas em imagens é outra estratégia utilizada para a detecção de objectos semelhantes em várias imagens. Esta estratégia é de grande uti-

lidade, visto que o agrupamento de fotografias é frequentemente efectuado pela veri-ficação de objectos comuns nas imagens.
Em 1999 Lu e Sajjanhar [Lu 1999] propõem um método de caracterização de ima-gens através das formas geométricas dos objectos nela contidos. Nesta solução, a representação geométrica é invariante em relação à escala, translação e rotação. No estudo também é comparada a solução com o método baseado no descritor de Fourier, obtendo o método deles melhor performance e maior precisão, mas custos computa-cionais idênticos.
Outro algoritmo de análise de formas geométricas numa imagem é apresentado em [Nabil 1996]. A estratégia explorada neste trabalho baseia-se nas relações espaciais entre os objectos da imagem, utilizando métodos de representação interna de projec-ção 2D. A ideia base deste método está no relacionamento das projecções dos diver-sos objectos da imagem nos eixos dos x’s e y’s. Uma 2D-PIR (2D-Projection Internal
Representation) é definida como um conjunto de 3 elementos (a,b,c), em que ‘a’ defi-ne uma relação topológica e ‘b’ e ‘c’ definem relações de intervalos nos eixos dos x’s e y’s respectivamente. Esta técnica constrói um grafo que relaciona os objectos da imagem através das 2D-PIRs. A similaridade entre imagens é então obtida através da comparação dos respectivos grafos. Através desta estratégia conseguimos extrair rela-ções entre objectos da imagem, que são boas medidas de calculo de similaridade. O maior problema desta abordagem é detectado quando temos duas imagens e uma delas é uma rotação ou reflexão da primeira. Nestes casos terá que ser detectada a existência de objectos idênticos nas duas imagens e posteriormente efectuar o posi-cionamento das imagens relativamente a esses objectos. Só então será possível aplicar o algoritmo e obter os resultados esperados.
2.2 Agrupamento Bseado em Eventos, Data/Tempo
Girgensohn et al propõem uma aplicação de organização de fotos baseada em eventos [Girgensohn 2003]. Nessa aplicação encontramos uma light table onde apresentam os thumbnails das diferentes fotos (ver Figura 1). Complementando a light table ainda dispomos de uma vista em árvore que suporta a navegação pela colecção. A divisão da colecção em diferentes categorias é efectuada pela detecção automática de eventos, sendo possível ajustar manualmente as fronteiras de cada evento.
Esta abordagem permite a organização em diversas categorias (ex.: pessoas, luga-res, eventos) através da filtragem de meta-informação associada às fotografias (infor-mação GPS ou reconhecimento de faces). Este género de filtragem é efectuado auto-maticamente quando este tipo de informação se encontra disponível. O utilizador ainda dispõe de mecanismos de criação de meta-informação através da associação manual das fotografias às categorias desejadas ou aos eventos criados. Estes autores defendem que, na maioria das vezes, a similaridade do conteúdo das imagens é menos significativa que a meta-informação para a detecção de eventos. No seguimento dessa ideia, adaptam o algoritmo proposto em [Cooper and Foote 2001] para realizar o clus-
tering das fotografias com timestamps semelhantes. A primeira etapa dessa técnica consiste na ordenação temporal das fotografias. Posteriormente é construída uma matriz de similaridades que contem valores de similaridade temporal entre as fotos a agrupar. As linhas e colunas da matriz são indexadas por foto, em ordem temporal, e a
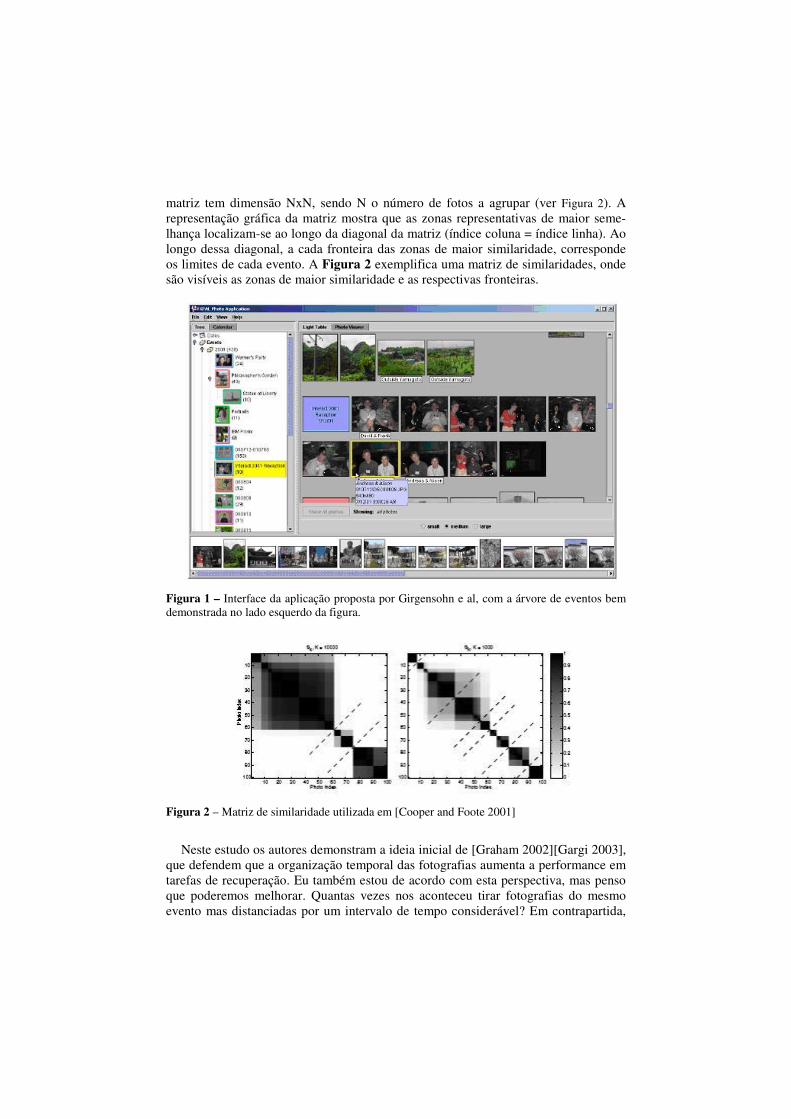
matriz tem dimensão NxN, sendo N o número de fotos a agrupar (ver Figura 2). A representação gráfica da matriz mostra que as zonas representativas de maior seme-lhança localizam-se ao longo da diagonal da matriz (índice coluna = índice linha). Ao longo dessa diagonal, a cada fronteira das zonas de maior similaridade, corresponde os limites de cada evento. A Figura 2 exemplifica uma matriz de similaridades, onde são visíveis as zonas de maior similaridade e as respectivas fronteiras.
Figura 1 – Interface da aplicação proposta por Girgensohn e al, com a árvore de eventos bem demonstrada no lado esquerdo da figura.
Figura 2 – Matriz de similaridade utilizada em [Cooper and Foote 2001]
Neste estudo os autores demonstram a ideia inicial de [Graham 2002][Gargi 2003],
que defendem que a organização temporal das fotografias aumenta a performance em tarefas de recuperação. Eu também estou de acordo com esta perspectiva, mas penso que poderemos melhorar. Quantas vezes nos aconteceu tirar fotografias do mesmo evento mas distanciadas por um intervalo de tempo considerável? Em contrapartida,

quantas vezes tiramos fotografias separadas por curto espaço de tempo mas que con-sideramos como pertencentes a eventos diferentes? Outro problema ainda mais comum acontece quando pretendemos juntar à nossa colecção, fotografias de um familiar ou amigo. Neste caso a nossa colecção expande e provavelmente passa a con-ter fotografias de eventos diferentes realizados em datas e tempos semelhantes. Se considerarmos eventos diferentes, talvez queiramos que sejam organizados separada-mente.
Outra impossibilidade deste sistema é a organização das fotografias por similarida-de de conteúdo. Ao considerarem apenas a meta-informação associada às fotografias limitam as possibilidades de associação entre imagens, e como é referido por diferen-tes investigadores, este tipo de informação não é muito frequente em fotografias e quando existe é muito reduzida.
Cooper et al apresentam-nos um método de clustering de colecções de fotos [Coo-per 2005], que vem no seguimento dos seus trabalhos anteriores, um dos quais foi apresentado acima. Este método já permite a divisão da colecção de fotos baseada apenas na similaridade temporal ou conjugando as características temporais com as características de conteúdo. Esta nova preocupação com o conteúdo das imagens vem no seguimento da tentativa de responder aos 3 maiores tipos de procuras efectuadas pelos utilizadores e reportadas por [Rodden and Wood 2003]:
1. procurar fotografias pertencentes a um determinado evento; 2. procurar uma fotografia em particular; 3. procurar um conjunto de fotografias pertencentes a diferentes eventos mas
que partilhem atributos semelhantes (ex:. determinada pessoa). Sem desprezar o conteúdo das imagens, o foco deste estudo localiza-se fundamen-
talmente na organização temporal das colecções fotográficas em várias escalas. A Figura 3 mostra a interface do sistema onde é visível a variação da escala de eventos através da árvore de eventos representada à esquerda. Este método é automático não necessitando de qualquer parâmetro de threshold ou treino. A similaridade é calculada entre todos os pares fotos numa vizinhança local e a avaliação dessa similaridade é efectuada para diferentes escalas temporais. A cada escala é calculado um valor de correlação para determinar novos pontos de informação que eles designam por “novel
scores”. As fronteiras de cada evento são determinadas através da escolha da melhor escala para segmentação da colecção. Por fim são apresentados alguns métodos para avaliação dos clusters associados às diferentes fronteiras detectadas.
Uma das limitações deste algoritmo de detecção de eventos é a sua complexidade quadrática no número de fotos. Para resolução desta restrição, são apresentadas duas variações: uma baseada no critério de informação de Bayes (Bayes information crite-
rion -BIC) e outra baseada em programação dinâmica. Apesar de não serem estudados resultados, a inserção da possibilidade de considerar semelhanças de conteúdo de imagem melhoram o agrupamento. Outro aspecto positivo desta abordagem é o facto de não utilizar thresholds ou outro género de assumpções, permitindo generalizar o sistema a diferentes tipos de colecções de imagens.

Figura 3 – Interface da aplicação proposta por [Cooper 2005], que propõe melhorias à aborda-gem de [Girgensohn 03]. Neste screen shot podemos observar o utilizador a ajustar os resulta-dos obtidos pela detecção automática de eventos.
O trabalho descrito por Platt em [Platt 2000], apresenta dois métodos de clustering,
o primeiro através da data e hora em que as fotos foram tiradas e o segundo através do conteúdo das imagens. A solução desenvolvida permite a utilização independente dos dois tipos de clustering ou a combinação de ambos. Uma das possibilidades de com-binação proposta baseia-se na utilização sequencial dos dois tipos de clustering: pri-meiro são criados grupos de fotos baseados no tempo e posteriormente para cada um desses grupos é efectuado o clustering através do conteúdo. O AutoAlbum (Figura 4), o sistema que implementa esta solução, utiliza agrupamento probabilístico para obter uma melhor performance de clustering baseado no conteúdo das imagens. O modelo probabilístico utilizado é o Left-Right Hidden Markov Model (HMM).
Novamente encontramos uma solução onde são propostos dois métodos de cluste-
ring que poderão ser utilizados simultaneamente e combinados de diversas maneiras. Essa combinação permitirá obter diferentes perspectivas de agrupamento, dado que a noção de agrupamento é muito subjectiva entre utilizadores.

Figura 4 – Interface da aplicação AutoAlbum
Em [Platt 2003] é apresentado o PhotoTOC (Photo table of Contents)(Erro! A
origem da referência não foi encontrada.), um sistema de organização de fotografias, que vem no seguimento do projecto AutoAlbum. Este sistema efectua o agrupamento de fotos através do clustering das datas de criação e das cores das fotografias. Os autores voltam a apresentar dois algoritmos de clustering: o primeiro é baseado no tempo de criação da fotografia para efectuar o agrupamento. O segundo é baseado no conteúdo, utilizando as cores da fotografia para detectar similaridades. Neste segundo algoritmo, o tempo de criação é apenas utilizado para ordenação das fotos e é a cor que é utilizada para efectuar o clustering. Os autores dão preferência à utilização do algoritmo baseado no tempo, utilizando o segundo como algoritmo de recurso, para quando a informação temporal não é credível.
No meu ponto de vista, esta abordagem torna-se bastante redutiva ao incentivar apenas a informação temporal. Tal como já havia dito atrás, o automatismo da gera-ção de agrupamentos de fotografias não poderá basear-se apenas na data de criação das fotografias. Caso assim seja, limitamos as possibilidades de formação de grupos, obtendo apenas grupos com similaridade temporal. Outro aspecto onde penso já haver soluções melhoradas é no modo como é feito o clustering. Neste sistema o algoritmo de clustering necessita de thresholds calculados empiricamente e as fotos não são comparadas entre todas. O algoritmo apenas ordena cronologicamente as fotos e efec-

tua comparações ao longo de uma janela de dimensão n, sendo n também calculado empiricamente (neste estudo foi utilizado o valor 10).
Figura 5 – PhotoToc: aplicação proposta por [Platt 2003]
Loui e Savakis apresentam-nos um algoritmo que automatiza a criação de álbuns
de fotografias [Loui and Savakis 2003], usando dois algoritmos base: um de cluste-
ring de eventos e outro de detecção de imagens de baixa qualidade. Aqui, iremos ape-nas analisar o algoritmo de clustering de eventos.
A técnica de clustering desenvolvida, utiliza a data e tempo para a detecção de eventos e conjuga a utilização da cor para agrupar as imagens de cada evento. Nesta abordagem os eventos são obtidos através de um algoritmo de clustering k-means [Jain and Dubes 1988]. Na análise da cor é utilizada uma técnica de correlação de his-togramas de cor baseados em blocos da imagem. O objectivo desta abordagem é a organização de fotografias em eventos e sub-eventos através de dois tipos de informa-ção: data e tempo de captura das fotos, reflectindo as actividades implícitas nas fotos, e na similaridade de conteúdo. O algoritmo utilizado demonstra ser útil na organiza-ção das nossas colecções quando pretendemos uma organização por eventos, e consi-derarmos um evento como uma actividade limitada por características temporais. A divisão dos eventos através da análise de conteúdo de imagem já permite uma apro-ximação a outro género de agrupamento, muitas vezes do interesse do utilizador, e

efectivamente complementa a organização temporal. Podemos observar os resultados desses dois tipos de análise através da Figura 7.
Figura 6 – Exemplos de fotografias comuns nas colecções dos utilizadores.
Figura 7 – Interface da proposta de agrupamento de [Loui e Savakis 2003]. É possível observar os agrupamentos efectuados às fotografias da Figura 6 onde são detectados 2 eventos.

Um aspecto que poderá ser melhorado corresponde à melhoria das técnicas de aná-lise de conteúdo. Poderá ser vantajoso a combinação de diferentes técnicas de extrac-ção de semelhanças de conteúdo. Este trabalho mostra-se limitado quando comparado com os objectivos de agrupamento propostos no nosso estudo. Os resultados obtidos por Loui e Savakis mostram-se bastante dependentes da característica temporal.
Encontramos ainda muitos outros apologistas da utilização do tempo como caracte-rística base na organização e browsing de fotos digitais pessoais. Todos estes estudos defendem a ideia de que fotos semanticamente relacionadas têm também um relacio-namento temporal [Graham 2002][Huynh 2005][Gargi 2003b].
2.3 Agrupamento Baseado em Anotações/Legendas
Kuchinsky et al desenvolveram o FotoFile (Figura 8), um sistema para recuperação e organização multimédia [Kuchinsky 1999]. Neste sistema, tal como eles referem, foi aplicada uma abordagem híbrida. Foram desenvolvidas diversas técnicas que facili-tam a tarefa de efectuar anotações, e que posteriormente serão utilizadas nas activida-des de organização e procura de elementos multimédia, incluindo fotografias. São também utilizadas várias técnicas de indexação baseadas no conteúdo das imagens, aumentando assim as capacidades de organização. O sistema proposto tenta combinar as vantagens das anotações efectuadas manualmente pelos utilizadores e as vantagens da extracção automática de características de conteúdo. Tal como na maioria dos tra-balhos nesta área, também neste estudo é consensual a importância e dificuldade ine-rente às anotações dos elementos multimédia. É nesse sentido que o FotoFile dispõe de mecanismos que facilitam a realização dessas anotações. Mas mesmo com o traba-lho facilitado, o utilizador terá que despender bastante atenção e tempo na anotação das fotos. A necessidade de anotação manual torna o sistema bastante dependente do utilizador e o conceito de automatização fica bastante relaxado. É por isso que a utili-zação de mecanismos de extracção de características, aumenta a automatização do processo e facilita a organização das fotos. Neste sentido, é de evidenciar o esforço realizado na análise de conteúdo, procurando detectar faces. Esta funcionalidade per-mite uma organização específica de fotografias, explorando bastante bem as potencia-lidades da análise de conteúdo.
Um aspecto ainda por analisar e fulcral para a análise do sucesso do sistema será o estudo comportamental dos seus utilizadores. Visto que o processo de anotação é a actividade que menos atrai os utilizadores na organização das suas colecções e sendo a razão para o desenvolvimento destes sistemas, será importantíssimo saber se os mecanismos implementados atraem os utilizadores para essa tarefa.

Figura 8 – Interface da aplicação FotoFile.
Em 2000 Liu et al apresentaram um sistema de gestão de fotografias familiares
denominado MiAlbum [Liu 2000a] (interface representada na Figura 9). Este sistema é baseado na anotação semiautomática das fotos. Liu Wenyin et al defendem que uma procura eficiente de imagens requer a ajuda das anotações, de modo a efectuar uma procura baseada em palavras-chave. Para tal é utilizado o método de anotação de imagens proposto em [Liu 200b]. O processo de anotação semiautomática encontra-se inserido nos processos de recuperação de imagens e respectivo feedback. Quando um utilizador pesquisa uma determinada fotografia através de um conjunto de palavras-chave, poderá proporcionar um feedback ao sistema relativamente à resposta que este lhe deu como resultado da pesquisa. Através deste feedback o sistema actualiza as relações entre as imagens e as palavras-chave utilizadas. Deste modo a anotação da base de dados do sistema é aperfeiçoada com o aumento progressivo de pesquisas e feedback.
Quando o utilizador importa novas fotografias, o sistema realiza uma pesquisa automática, procurando as fotografias do álbum que mais se assemelhem visualmente às imagens importadas. Essa pesquisa é efectuada utilizando as tradicionais técnicas de recuperação de imagens baseada no conteúdo. Obtidas as imagens mais semelhan-tes, são seleccionadas as palavras-chave mais frequentes nesse grupo de imagens e associadas à nova fotografia. Essa associação só será validada pelo utilizador através do feedback de uma futura pesquisa. A ideia traduzida neste sistema está direccionada

à procura de imagens específicas. O utilizador quando pretende visualizar um conjun-to de fotografias já tem de ter especificado um objectivo, que traduzirá numa palavra-chave de pesquisa. No nosso caso pretendemos gerar associações entre imagens para permitir ao utilizador observar a sua colecção inteira através desse agrupamento de associações. No nosso estudo o objectivo não será uma imagem específica mas permi-tir ao utilizador uma organização da sua colecção fotográfica que vá de encontro aos seus objectivos.
Outro problema desta abordagem foca-se no facto do sistema necessitar de ser uti-lizado bastantes vezes para produzir resultados aceitáveis. Com este sistema não con-seguimos ter uma organização da colecção imediatamente após importarmos as nos-sas fotos. Se não tivermos o sistema treinado, não conseguiremos criar um álbum com as fotografias que acabámos de descarregar dos nossos dispositivos fotográficos. O ponto positivo a retirar deste sistema reflecte-se na possibilidade do utilizador dar feedback às operações efectuadas automaticamente.
Figura 9 – MiAlbum: Interface da solução proposta por [Liu 2000a]
2.4 Agrupamento por Conteúdo de Imagem
Gargi et al [Gargi 2003a] apresentam algumas técnicas de gestão e procura em colec-ções de imagens digitais. Apesar de não se focar muito em métodos automáticos de organização e agrupamento de imagens, este estudo explora bem a necessidade do uti-lizador ter ao seu dispor diferentes formas de agrupar as fotos. A gestão de fotografias proposta neste trabalho incide bastante na possibilidade de oferecer diferentes pers-pectivas da colecção. O método usual de organização temporal é expandido a uma

organização mais flexível, de acordo com o propósito do utilizador. Neste trabalho é também abordado o problema de gestão de álbuns criados. A ligação entre cada álbum e os ficheiros das imagens é efectuada através de ligações que permitem a actualização dos álbuns quando uma foto é movida ou removida. É introduzido ainda o conceito de “álbum virtual”, que define o conjunto de ligações que definem a pers-pectiva de cada álbum em relação à colecção. Nos processos de procura disponibili-zam técnicas de similaridade baseadas na meta-informação disponibilizada pelas câmaras fotográficas, nas características de baixo-nível das imagens e na detecção de faces. Sendo estas técnicas utilizadas na procura de imagens, será útil inclui-las na automatização do agrupamento das mesmas.
Figura 10 – Interface de pesquisa de fotografias proposta por [Gargi 2003ª]
No trabalho de Lu et al apresentado em [Lu 2004], podemos observar uma das
poucas abordagens deste problema que não está estritamente dependente das caracte-rísticas temporais. Neste estudo são apresentadas técnicas de organização e clustering de fotos utilizando o domínio da frequência DCT (Transformada Discreta do Coseno - Discrete Cosine Transform). Esta técnica utiliza os primeiros coeficientes DCT dife-rentes de zero para calcular histogramas de energia no domínio da frequência. A simi-laridade entre as fotos é obtida através da comparação desses histogramas. Esta pers-pectiva permite a organização das fotos através do seu conteúdo, obtendo resultados satisfatórios, tal como podemos observar no exemplo da Figura 11. Se combinarmos este método com os restantes métodos de extracção de características, poderemos aperfeiçoar a detecção de similaridades e consecutivamente melhorar esta técnica de agrupamento. Esta abordagem vem resolver algumas lacunas de alguns dos estudos

anteriores, evidenciando que a similaridade de conteúdos de imagens é importante para o utilizador organizar as suas colecções [Rodden 2001].
Figura 11 – Interface do sistema de [Lu 2004] (esquerda) e resultados do agrupamento efec-tuado pelo sistema (direita).

3 Discussão
Tal como é possível observar pela Erro! A origem da referência não foi encontrada., existem diversas formas de agrupamento de fotografias: baseadas no tempo, baseadas no conteúdo e baseadas nas anotações e legendagem efectuadas às fotografias.
Já de seguida apresentamos a Tabela1 que facilitará o acompanhamento desta “Discussão”. Na Tabela 1 é resumida cada uma das abordagens descritas e analisadas anteriormente. Para cada estudo são assinaladas as características em que se apoiam as técnicas de agrupamento desenvolvidas (tempo, cor, textura, forma, detecção de faces, meta-informação e informação semântica). Na última coluna da tabela é apre-sentado o foco de estudo de cada abordagem, por exemplo: em [Cooper 2005] são uti-lizadas características temporais e características de conteúdo de imagem, sendo que a ideia base de agrupamento centra-se na informação temporal.
Tabela 1 – trabalhos mais relevantes de agrupamento de imagens.
Time
Features Color
Features Texture Features
Shape Features
Detecção de faces
Meta-informação
Informação Semântica
Foco
[Girgensohn 2003]
� - - - � - - Detecção eventos (data/tempo)
[Cooper 2005]
� (1) - - Detecção eventos (data/tempo)
[Platt 2000] � � � � - - - Detecção eventos (data/tempo)
[Platt 2003] � � - - - - - Detecção eventos (data/tempo)
[Loui and Savakis 2003]
� � - - - - - Detecção eventos (data/tempo)
[Kuchinsky 1999]
- � � � � - � Utilização de ano-tações/legendas
[Liu 2000a] - (2) - - � Utilização de ano-tações/legendas
[Gargi 2003a]
� � � � � (3) - Detecção eventos
(data/tempo) e agru-pamento por conteúdo
[Lu 2004] - � - - - - - Análise da cor
através de histogra-mas de energia
1 o algoritmo possibilita a inserção de descritores de características de baixo-nível no calculo de simi-laridades mas não é efectuado nenhuma abordagem a estas características.
2 Nesta abordagem apenas utilizam as tradicionais técnicas de content based retrieval durante a impor-tação de novas fotografias, para obterem informação meta-informação.
3 Este método utiliza informação específica disponibilizada pelas máquinas fotográficas: aperture e SubjectDistance.
A maioria das abordagens aposta na importância da data/tempo na organização das
fotografias. Neste tipo de perspectiva conseguimos facilmente aproximar a organiza-ção das fotografias digitais à organização normalmente efectuada com as fotografias em papel. Este género de agrupamento é um dos mais utilizados pelos utilizadores e consequentemente é exigido a qualquer aplicação de gestão de fotografias que a ofe-

reça. No entanto, esta é uma abordagem que reduz bastante as capacidades de organi-zação de fotografias dos utilizadores, mas se associada a outros métodos de agrupa-mento poderá originar agrupamentos eficazes e interessantes. Esta técnica poderá ainda ser utilizada como agrupamento base e posteriormente ser utilizado outro género de sub agrupamentos. Por outro lado, poderemos utilizar este e outros tipos de agrupamento e aplicá-los no mesmo nível, atribuindo pesos diferentes a cada um dos métodos, de modo a adaptar o mecanismo de agrupamento a cada utilizador.
Mas será que a organização por eventos satisfaz suficientemente os utilizadores? A resposta a esta pergunta é não, como está argumentada em [Rodden2001][Rodden and Wood 2003]. A organização por eventos não satisfaz as necessidades dos utilizadores. O utilizador frequentemente cria associações entre fotografias distantes no tempo e pertencentes a eventos distintos. Para complementar a falha existente nas abordagens por eventos foram estudadas as propostas de análise semântica e análise de conteúdo.
Nos sistemas FotoFile [Kuchinsky 1999] e MiAlbum [Liu 2000a], é focada a importância da informação semântica associada às fotografias. Este género de infor-mação embora seja bastante difícil de obter porque exige bastante trabalho por parte dos utilizadores, é informação importante na descrição das fotos. Esta é uma das melhores formas que o utilizador tem para descrever o contexto em que a fotografia foi tirada. O contexto é uma característica fundamental no agrupamento de fotogra-fias. O grande inconveniente da organização semântica está na dependência do utili-zador para a legendagem das fotos. Nestes dois sistemas referidos existe um esforço na automatização da criação de anotações das fotos, diminuindo o trabalho realizado pelos utilizadores. Apesar de originar anotações e legendas menos precisas que as anotações e legendas realizadas pelos utilizadores, estas abordagens permitem utilizar a potencialidade da informação semântica, e combinar essa informação com a infor-mação extraída na comparação das restantes características das imagens. A introdução da informação semântica no agrupamento automático das fotografias permite o corre-lacionamento dos contextos das fotografias. Apesar de importante, a adopção desta abordagem necessita de ser complementada com outro tipo de agrupamento que torne o agrupamento mais eficaz ou que possa ser utilizado como recurso quando nos depa-rarmos com a habitual falta de informação semântica.
Nos dois últimos trabalhos apresentados [Gargi 2003a][Lu 2004], são analisadas com maior pormenor as características de conteúdo das imagens. A análise de conteú-do de imagens pode ser efectuada por inúmeras técnicas, onde cada uma delas extrai características específicas. Este género de extracção de similaridades e relacionamen-to de imagens, é bastante utilizado na área da recuperação de imagens (CBIR) e pode ser eficazmente introduzido no agrupamento de fotografias digitais. A análise e com-paração do conteúdo das fotografias, permite criar grupos de fotos com semelhanças no aspecto visual. A comparação visual das imagens possibilita o relacionamento de imagens que podem ser temporal e semanticamente distintas, cobrindo mais um tipo de agrupamento.
Para além dos baixos custos da fotografia digital, a representação digital de foto-grafias veio proporcionar ao utilizador outro tipo de vantagens, como por exemplo o aumento do número de fotografias das colecções ou a utilização de diversos tipos de organização simultânea das fotografias. Gargi et al defende em [Gargi 2003a] a intro-dução de um novo conceito de organização fotográfica denominado álbum virtual, que permite melhorar a organização de fotografias, na medida em que podemos ter

diversas perspectivas da mesma colecção fotográfica em substituição da organização usual dos álbuns tradicionais. Em vez de continuarmos a utilizar apenas um tipo de agrupamento, tal como acontecia com as fotografias em papel onde utilizávamos o agrupamento por eventos, passamos a dispor de diversas maneiras de agrupar e orga-nizar as fotos. Passamos a poder ter uma fotografia pertencente a diversos álbuns. É nesse sentido que será importante conciliar as técnicas utilizadas pelos três conjuntos de agrupamento. Esse novo tipo de agrupamento permitirá qualquer um dos agrupa-mentos demonstrados nas abordagens descritas, permitindo ainda a conjugação dos mesmos.
Se pegarmos nas ideias de anotação semântica de [Kuchinsky 1999][Liu 2000a] e nas ideias de conteúdo de imagem de [Gargi 2003a][Lu 2004] e as inserirmos nas téc-nicas utilizadas pelo grupo de detecção de eventos, acrescentamos valor a cada uma das técnicas quando utilizadas de modo independente. Outra possibilidade de melho-ramento será ainda a introdução das técnicas de recuperação de imagem (CBIR), que possibilitam o aumento de performance e eficácia na detecção de similaridades.
Tendo como objectivo o desenvolvimento de diversas possibilidades de agrupa-mento, teremos que considerar todas as abordagens de uma possível integração. Obtendo uma integração eficaz das estratégias, conseguiremos um sistema de geração de diferentes tipos de álbuns virtuais, onde cada um destes álbuns reflecte uma pers-pectiva da colecção de fotografias. Assim o utilizador poderá seleccionar o ou os que mais se enquadram com os seus objectivos.
Por fim, estudadas as abordagens mais relevantes de agrupamento de fotografias e analisadas as falhas de cada uma delas será altura de propor uma solução que concilie a resolução das falhas encontradas e implemente as ideias já referidas durante a dis-cussão dessas mesmas soluções.
Enquanto a maioria dos estudos desenvolvidos focam o agrupamento das fotos num determinado conjunto específico de características, no sistema que irei desenvol-ver, tentarei abranger técnicas que sejam capazes de identificar fotos tiradas no mes-mo contexto ou em contextos muito próximos. Seguindo a ideia de [Rodden 2001], que refere a necessidade de agrupamento de fotos por similaridade, e contrariamente a muitas das abordagens efectuadas, também terei elevada preocupação com a análise de conteúdo das fotografias. Outro aspecto a evidenciar neste novo sistema será a possibilidade do utilizador parametrizar os pesos que cada tipo de análise terá no pro-cesso de agrupamento.
Após implementadas as técnicas de extracção de características implementarei mecanismos que facultem ao utilizador a definição do tipo de agrupamento desejado. Esta personalização dos métodos de agrupamento será efectuada através da atribuição de pesos distintos para cada tipo de descritor extraído das imagens. Finalmente efec-tuarei avaliações experimentais que validem o sistema e permitam obter parametriza-ções por omissão a atribuir aos tipos de agrupamentos mais comuns.
Resumindo, a minha solução focará principalmente as características temporais, as características de baixo-nível e a meta-informação disponível nas fotografias. Diver-sas técnicas de CBIR serão consideradas na extracção de descritores de conteúdo das fotografias. Posteriormente estudarei a detecção de faces para permitir o agrupamento de fotos através das personagens nelas contidas. As características semânticas serão também focadas mas nunca esquecendo que a sua existência requer elevado esforço do utilizador, contrariando o conceito de automatização de agrupamento.

Esta solução tentará criar uma entrada na tabela 1 onde todas as colunas, ou quase todas estejam preenchidas e o foco da solução seja não só um tipo de característica mas o maior conjunto de características.
4 Conclusão
Neste documento tentou abordamos o tema da fotografia digital, em particular os pro-blemas de gestão e organização de colecções fotográficas. O elevado crescimento de colecções fotográficas provocado pelo aparecimento da fotografia digital originou a procura de soluções que facilitem os processos de agrupamento e organização das colecções fotográficas.
Neste documento analisamos os comportamentos e as necessidades dos utilizado-res relativamente à actividade fotográfica. Em conformidade com esses comporta-mentos e necessidades analisamos alguns dos trabalhos mais relevantes na área do agrupamento, organização e gestão de colecções fotográficas. Nesse conjunto de tra-balhos destacam-se três tipos de soluções de agrupamento: através de informação temporal, através de informação semântica (legendas, anotações), e agrupamento por conteúdo de imagens. Associado a este último grupo de soluções está a área de recu-peração de imagens (CBIR), razão pela qual também foi objecto de estudo.
Em cada uma das soluções analisadas observamos uma preocupação constante com um conjunto de características da imagem, razão pela qual foi possível dividir as soluções estudadas nos grupos referidos anteriormente. Nenhum desses trabalhos desenvolveu uma solução que desse igual ênfase aos três tipos de características de imagem. Cada uma das soluções apresentadas nesses trabalhos, ao focar-se numa determinada área, limita os tipos de agrupamento possíveis, tornando o sistema pouco flexível em relação aos interesses dos utilizadores. Sendo assim, o conjunto de traba-lhos analisadas permitem agrupamentos fundamentados em informação temporal, informação semântica e aspecto visual, mas nenhum deles tenta criar uma solução focada na combinação eficiente desses três tipos de informação.
É nesse sentido que apresento aqui uma ideia para a minha solução, que combina os diferentes tipos de informação de modo a permitir conciliar as vantagens de cada abordagem, eliminado as respectivas lacunas. Esta solução tentará dar maior liberdade ao utilizador para escolher o agrupamento de fotos que melhor se adequa aos seus interesses.
Referências
[Alghbari 2006] Zaher Al Aghbari, Ruba Al-Haj. Hill-Manipulation: An effective algorithm for color image segmentation. Image and Vision Computing. 2006
[Chitkara 2000] Vishal Chitkara, Mario A. Nascimento, Curt Mastaller. Technical Report TR 00-18, Department of Computing Scince, University of Alberta, Edmonton, Alberta, Canada. September 2000
[Cooper 2005] Mtthew Cooper, Jonathan Foote, Andreas Girgensohn, and Lynn Wilcox. Temporal Event Clustering for Digital Photo Collections. ACM Transactions on Multimedia Computing, Communications and Applications, Vol. 1, No. 3, August 2005, pages 269-288

[Cooper and Foote 2001] M. Cooper, and J. Foote. Scene Boundary Detection Via Video Self-Similarity Analysis. Proc. IEEE Intl. Conf. on Image Processing, 2001, pp. 378-381
[Frohlich 2002] D. Frohlich, A. Kuchinsky, C. Pering, A. Don, and S. Ariss. Requirements for photoware. In Proceedings of the ACM Conference on CSCW. ACM Press, New York, NY, 166-175, 2002
[Gargi 2003a] Ullas Gargi, Yining Deng and Daniel R. Tretter. Managing and Searching Personal Photo Collections. Proc. SPIE Storage and Retrieval for Media Databases, 2003, pp.13.21
[Gargi 2003b] Ullas Gargi. Consumer Media Capture: Time-based Analysis and Event Clustering. Technical Report HPL-2003-165, HP Laboratories, August 2003.
[Girgensohn 2003] Andreas Girgensohn, John Adcock, Matthew Cooper, Jonathan Foot & Lynn Wilcox. Simplifying the Management of Large Photo Collections. Human-Computer Intereaction, INTERACT’03. Publicado pelo IOC Press, (c) IFIP, 2003, pp. 196-203
[Graham 2002] A. Graham, H. Garcia-Molina, A. Paepeke, and T. Wino-grad. Time as the Essence for Photo Browsing Throught Personal Digital Libraries. Proc. Joint Conf. on Digital Libraries, 2002, pp. 326-335
[He and Wang 1990] D. C. He and Li Wang. A new statistical approach for texture analysis. Photogrammatic Engineering and Remote Sensing. 56(1):61-66, 1990.
[He and Wang 1991] D. C. He and Li Wang. Texture filters based on texture spectrum. Pattern Recognition. 24(12): 1187-1195, 1991
[Huang 1997] J. Huang, S. Ravi Kumar, Mandar Mitra, Wei-Jing Zhu, Ramin Zabih. Image indexing using color correlograms. in Proc. IEEE Computer Vision and Pattern Recognition Conf., San Juan, PR, June 1997, pp. 762–768.
[Huynh 2005] David F. Huynh, Steven M. Drucker, Patrick Baudisch, Curtis Wong. Time Quilt: Scaling up Zoomable Photo Browsers for Large, Unstructured Photo Collections. CHI 2005, April 2-7, 2005, Portland, Oregon, USA
[Jain and Dubes 1988] A. Jain and R. Dubes. Algorithms for Clustering Data. Englewood Cliffs, NJ: Prentice-Hall, 1988, pp. 96-101
[Jalaja 2005] K. Jalaja, Chakravarthy Bhagvati, B. L. Deekshatulu, Arun K. Pujari. Texture Element Feature Characterizations for CBIR. Geoscience and Remote Sensing Symposium, 2005. IGARSS '05. Proceedings. 2005 IEEE International. 25-29 July 2005
[Kirk 2006] David S. Kirk, Abigail J. Sellen, Carsten Rother and Kenneth R. Wood. Understanding Photowork. CHI 2006 Procedings. Collecting and Editing Photos. April 22-27, 2006, Montréal, Québec, Canada.
[Kunchinsky 1999] Allan Kuchinsky, Celine Pering, Michael L. Creech, Dennis Freeze, Bill Serra, Jacek Gwizdka. Hewlett Packard Laboratories. FotoFile: A Consumer Multimedia Organization and Retrieval System. CHI’99, Pittsburg PA USA.
[Liu 2000a] Liu Wenyin, Yanfeng Sun, Hongjiang Zhang, Microsoft Research China. MiAlbum – A System for Home Photo Management Using the Semi-Automatic Image Annotation Approach. International Multimedia Conference. Proceedings of the eighth ACM international conference on Multimedia, 2000, Los Angels CA USA
[Liu 2000b] LiuWenyin, Susan Dumais, Yanfeng Sun, HongJiang Zhang, Mary Czerwinski and Brent Field. A Semi-Automatic image Annotation Strategy and its Performance Evaluation. Microsoft Technical Report. 2000
[Loui and Savakis 2003] Alexander C. Loui and Andreas Savakis. Automated Event Clustering and Quality Screening of Consumer Pictures for Digital Albuming. IEEE Transactions on Multimedia, 2003, vol5, pp. 390- 402.
[Lu 1999] Guojun Lu, Atul Sajjanhar, Region-basedshape representation and similarity measure suitable for content-basedimage retrieval, Multimedia Syst. 7 (2) (1999) 165–174.
[Lu 2004] Yang Lu, Tien-Tsin Wong, and Pheng-Ann Heng. Digital Photo Similarity Analysis in Frequency Domain and Photo Album Compression. ACM International Conference

Proceeding Series, Proceedings of the 3rd international conference on Mobile and ubiquitous multimedia, 2004
[Nabil 1996] Mohammad Nabil, Anne H. H. Ngu, and John Shepherd. Picture Similarity Retrieval Using the 2D Projection Internal Representation. IEEE Transactions on Knowledge and Data Engineering, Vol.8, No.4, pp. 533-539. 1996
[Platt 2000] John C. Platt. AutoAlbum: Clustering Digital Photographs using Probabilistic Model Merging. In Proc. IEEE Workshop on Content-Based Access of Image and Video Libraries, 2000, pp.96-100
[Platt 2003] John C. Platt, Mary Czerwinski, Brent A. Field. PhotoTOC: Automatic Clustering for Browsing Personal Photographs. Microsoft Research Technical Report MSR-TR-2002-17, 2003
[Rodden 2001] K. Rodden, Wojciech Basalaj, David Sinclair, and Kenneth Wood. Does Organization by Similarity Assist Image Browsing? In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems 2001, pp.190-197
[Rodden and Wood 2003] K. Rodden and K. Wood. How do people manage their digital photographs? In Proceedings of the ACM Conference on Human factors in Computing Systems (CHI). ACM Press, New York, NY, 409-416, 2003
[Saha 2004] Sanjoy Kumar Saha, Amit Kumar Das, and Bhabatosh Chanda. Cbir using perception based texture and colour measures. 17th International Conference on Pattern Recognition, pages 985–988, 2004.
[Shah 2004] Biren Shah, Praveen Dhatric, Vijay Raghavan. Using Inverse Image Frequency for Perception-Based Color Image Quantization. Image Analysis and Interpretation, 2004. 6th IEEE Southwest Symposium, 28-30 March 2004, pp. 71-75
[Smith and Chang 1995] John R. Smith and Shih-Fu Chang. Singe Color Extraction and Image Query. Proc. IEEE Int'l Conf. Image Processing, pp. 528-531, 1995.
[Wei 2005] Shikui Wei, Yao Zhao, Zhenfeng Zhu. Meaningful Regions Segmentation in CBIR. IEEE Int. Workshop VLSI Design & Video Tech, Suzhou, China, May, 28-10, 2005.